Abstract
Multimodal large language models are increasingly used as agent backbones that understand multimodal inputs, plan retrieval actions, invoke external tools, and reason over retrieved information.
Yet existing benchmarks rarely evaluate this ability in short-video applications, where a paused frame is often visually ambiguous and answering requires vertical, long-tail, and fast-evolving domain knowledge.
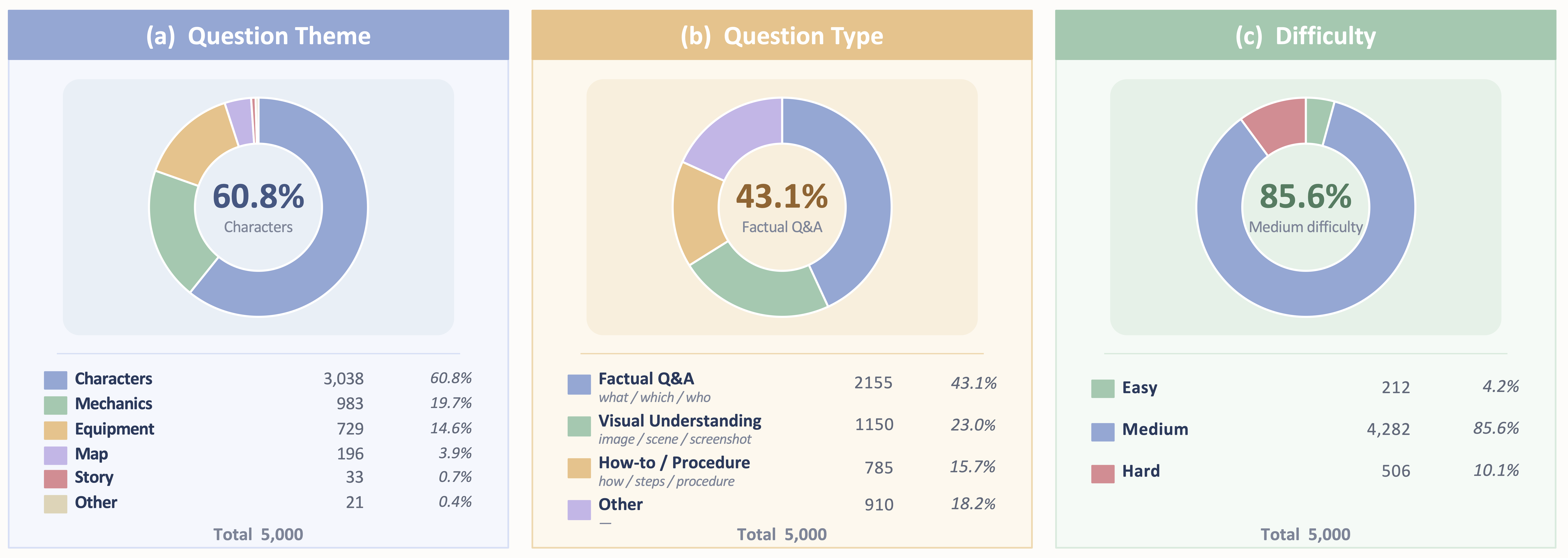
We introduce SVFSearch, the first open benchmark for short-video frame search in the Chinese gaming domain. SVFSearch contains 5,000 four-choice test examples and 4,198 auxiliary training examples, each centered on a paused game scene from a real short-video clip.
To support fair and reproducible evaluation, SVFSearch provides a frozen offline retrieval environment with a game-domain text corpus, a topic-linked image gallery, and text, image, and multimodal retrieval interfaces, avoiding reliance on uncontrolled web search APIs.
We evaluate representative paradigms ranging from direct QA and RAG workflow to Plan-Act-Replan agents and learned search models.
Results reveal a large gap between model-only answering, practical agentic search, and oracle knowledge: the best open-source direct-QA model reaches 66.4%, the best practical agent achieves 79.1%, and oracle knowledge reaches 95.4%.
Further analysis exposes bottlenecks in visual grounding, retrieval quality, evidence-grounded reasoning, and tool-use behavior, including over-search, answer-only shortcuts, and retrieval-induced misleading.